
Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) is a way of differentiating humans and machines and was coined by von Ahn, Blum, Hopper, and Langford [5]. The core idea is that reading distorted letters, numbers, or images is achievable for a human but very hard or impossible for a computer. CAPTCHAs might look like the one below. Most likely the reader has already seen one, when trying to register at a website or write a comment online.

There are several use cases for CAPTCHAs, which includes the ones presented in [6]: Preventing comment spam, protect website registration, protect e-mail addresses from scrappers, protect online polls, preventing dictionary attacks, and block/hinder search engine bots.
CAPTCHAs do not give a guarantee that it prevents these cases every time as there are known attack vectors. These include cheap or unwitting human labor, insecure implementation, and machine learning based attacks. We will not go into detail on insecure implementations, as the focus of this article are deep learning based approaches.
Human-based CAPTCHA breaking
Out of curiosity and to compare results achieved by machine learning approaches, we take a look at the human based approach. For example BypassCAPTCHA offers breaking CAPTCHAs with cheap human labor in packages (e.g. 20,000 CAPTCHAs for 130$). There are also other services including Image Typerz, ExpertDecoders, and 9kw.eu. There are also hybrid solutions that use both OCR and human labor like DeathByCAPTCHA. These vendors list the following accuracies and response times (averages):
| Service | Accuracy (daily average) | Response Time (daily average) |
|---|---|---|
| BypassCAPTCHA | N/A | N/A |
| Image Typerz | 95% | 10+ sec |
| ExpertDecoders | 85% | 12 sec |
| CAPTCHABOSS (premium version of ExpertDecoders) | 99% | 8 sec |
| 9kw.eu | N/A | 30 sec |
| DeathByCAPTCHA | 96.8% | 10 sec |
The values are advertised and self-reported. We did not conduct any verification of the stated numbers, but it can give an orientation on human performance and serves as a reference for our machine learning algorithms.
Learning-based CAPTCHA breaking
CAPTCHAs are based on unsolved or hard AI problems. However, with the progress of AI techniques and computing power, sequences of characters or CAPTCHAs can be recognized as shown by Goodfellow et al. in [1], Hong et al. in [2], Bursztein et al. in [3] and [7], and Stark et al. in [4] using deep learning techniques. Goodfellow et al. predict numbers from Goolge Street View images directly (without pre-processing) utilizing a CNN. They make use of DistBelief by Dean et al. to scale the learning to multiple computers and to avoid out of memory issues [1]. This technique was later on used to solve CAPTCHAs, whereby the researched achieved an accuracy of up to 99.8%. Hong et al. pre-process CAPTCHAs to rotate them and segment the characters. Afterwards they apply a CNN with three convolutional layers and two fully connected layers [2]. Bursztein et al. use pre-processing, segmentation, and recognition techniques (based on KNN) and later on various CNNs to detect CAPTCHAs from multiple websites including Baidu, Wikipedia, reCAPTCHA, and Yahoo [3],[7]. Stark et al. researched a way of detecting CAPTCHAs with limited testing data. They use a technique called Active Learning to feed the network with new training data, where the added data has a high classification uncertainty, to improve the performance overall [4]. The below table gives an overview of the reported accuracies in the different papers and blog posts.
| Researcher | Dataset | Technique | Accuracy (maximum) | Reference |
|---|---|---|---|---|
| Goodfellow et al. | Google Street View image files | CNN with DistBelief | 96% | [1] |
| Hong et al. | Microsoft CAPTCHAs | Preprocessing, segementation and CNN | 57% | [2] |
| Stark et al. | Cool PHP CAPTCHA generated CAPTCHAs | CNN with Active Deep Learning | 90% | [4] |
| Bursztein et al. | Baidu, CNN, eBay, ReCAPTCHA, Wikipedia, Yahoo CAPTCHAs | Reinforcement Learning, k-Nearest Neighbour | 54% (on Baidu) | [7] |
| Bursztein | Simple CAPTCHA | CNN | 92% | [3] |
| Bursztein | Simple CAPTCHA | RNN | 96% | [8] |
Current state of CAPTCHAs
Google has introduced NoCAPTCHA in December 2014. This introduces multiply new features including evaluation based on cookies, movement of the mouse, and recognition of multiple images. Google announced to introduce an invisible CAPTCHA to get rid of the checkbox.
The previous version of reCAPTCHA was very popular on many websites. It included typically two words with rotation and had an audio option. Further CAPTCHA techniques can include simple logic or math questions, image recognition, recognition of friends (social CAPTCHA), or user interaction (like playing a game) [9].
Our objectives and motivation
The aim of the project is to break CAPTCHAs using deep learning technologies without pre-segmentation. Initially we focus on simple CAPTCHAs to evaluate the performance and move into more complex CAPTCHAs. The training dataset is generated from an open source CAPTCHA generation software. Tensorflow is used to create and train a neural network.
Creating the datasets
We are generating the datasets using a Java based CAPTCHA generator (SimpleCAPTCHA). We have created the following datasets.
| Description | Size | Training samples | Test samples |
|---|---|---|---|
| Digits only | 38 MB | 9502 | 100 |
| Digits and characters | 197 MB | 49796 | 100 |
| Digits and characters with rotation | 39 MB | 10000 | 100 |
| Digits and characters with rotation | 198 MB | 49782 | 500 |
| Digits and characters with rotation | 777 MB | 196926 | 500 |
Each dataset contains jpeg images containing a CAPTCHA with five characters. The characters are lowercase (a-z) or numbers (0-9). We used the fonts "Arial" and "Courier" with noise. An example of the created CAPTCHAs is displayed below. Our intention was to mimic the CAPTCHAs created by Microsoft. We have extended SimpleCAPTCHA library in order to get character rotation, outlines in CAPTCHAs to achieve the same look of Microsoft CAPTCHAs.



Generated CAPTCHAs will be 152x80 greyscale images. This resolution is chosen because it is small enough to reduce memory footprint when training the CNN and it is also enough to recognize the CAPTCHA easily.
Deep CNN model
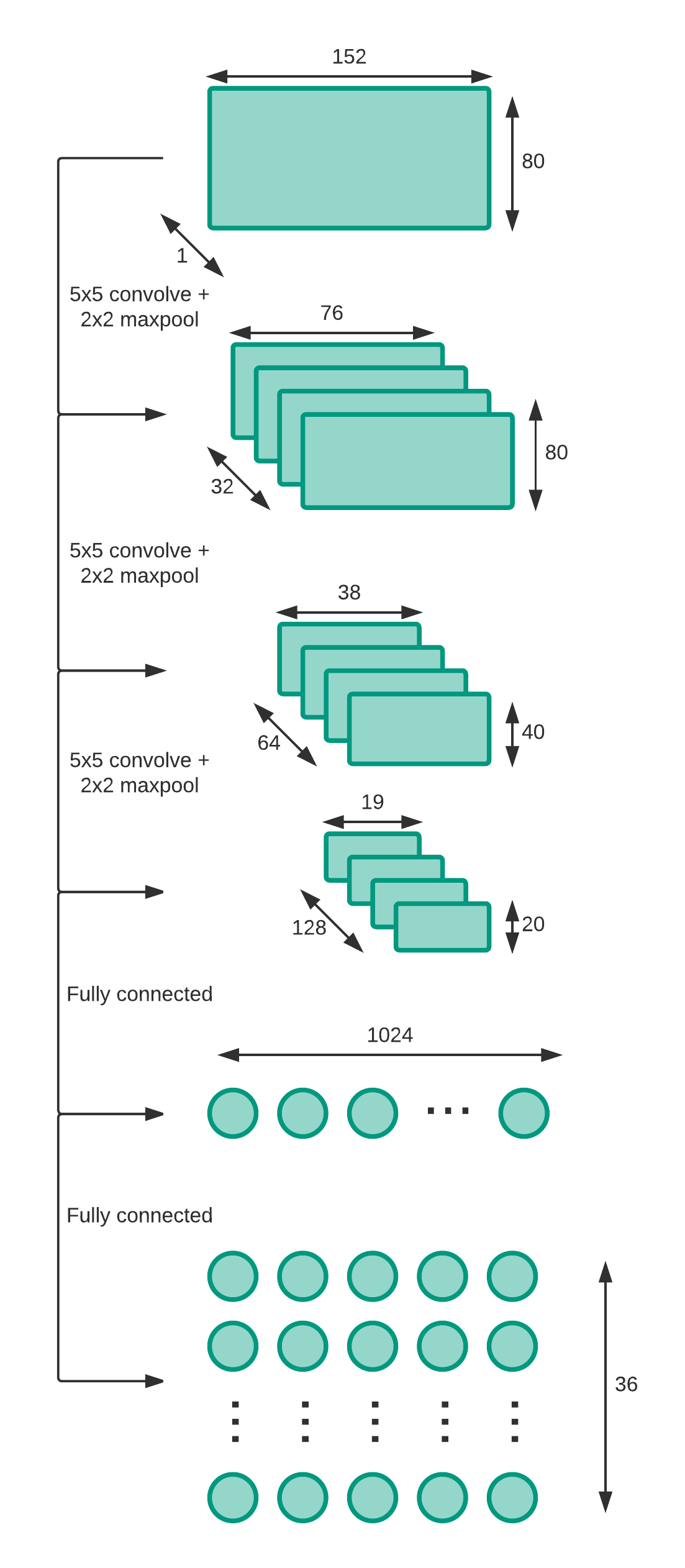
Based on the research in [1], [3] and [4] we use a deep CNN with three ReLU layers and two fully connected layers to solve the CAPTCHAs. Each digit is represented by 36 neurons in the output layer. The three convolutional layers with ReLU activation function have the sizes of 32, 64, and 128. 5x5 filter size was used in all layers. After each convolutional layer there is a max pooling of 2. After the last convolutional layer, there is a fully connected layer with ReLU of size 1024 and finally another fully connected layer that has an output size of 180. In the ReLU layers, a dropout of 0.75 is applied.
In the output layer, digits 0-9 will be represented by 1 to 10 neurons and, characters a to z will be represented by 11 to 36 neurons. Therefore, there are 5 x 36 neurons which will identify the CAPTCHA. The network will output the predictions for all 5 digits and each digit is calculated by the max probability of its 36 neurons. We have set the learning rate as 0.001.
Results and discussion
First, we trained the CNN with 10000 five letter and digit CAPTCHAs without rotation on a GTX660M. We had 100 batches with a batch size of 100 and ran it for 20 epochs. The hyperparameters were set as described in the previous section. The figure below shows that the network did not perform well with these settings. We then increased the training size to 50000 CAPTCHAs, but the results stayed the same. We then tried with 10000 simplified CAPTCHAs with only five digits without rotation. However, this still did not improve our situation. We noted that the loss function reduced quite quickly and stayed constant. We hence introduced another convolutional layer to the network to allow it to further differentiate the digits. Again, this resulted in almost the same result.

CNN with three conv. layers and two fully connected layers accuracy of CAPTCHAs with five digits or lowercase letters without rotation. Training in 100 batches and 10000 training samples.
These results match the ones presented in [4]. The authors then introduce Active Learning to circumvent the problem. In [1] a larger amount of samples is used. However, we do not have sufficient computing power available to use millions of images as training data. Also, in [3] the batch size is larger, resulting in a considerably higher accuracy. We decided to change our batch size, but required a more powerful GPU for that. Hence, we used a Nvidia Tesla K80 from AWS to conduct our training. We also changed the CNN back to three conv. layers and two fully connected layers. On the simple case with five digit CAPTCHAs without rotation we used 39250 CAPTCHAs in 157 batches and 10 epochs. We conducted testing with a very small dataset of 100 CAPTCHAs. The results did improve considerably as shown in the figure below. We managed to achieve a best training error of 94.9% and a test error of 99.2%. The very high test accuracy is quite likely also caused by the small amount of test items. However, running a K80 in AWS is quite costly and therefore we kept the test set to a minimum also in the upcoming experiments.

CNN with three conv. layers and two fully connected layers accuracy of CAPTCHAs with five digits without rotation. Training in 157 batches, 39250 training samples, and testing with 100 CAPTCHAs.
We then tried with a bit more complex CAPTCHAs with digits and lowercase characters. We used 49750 training and 100 test CAPTCHAs with the same CNN used in the simple case above. The figure below presents our results and shows that we can achieve a training accuracy of 65% and a test accuracy above 80% in these cases. We stopped the CNN prematurely after 10 epochs to try more complex use cases.
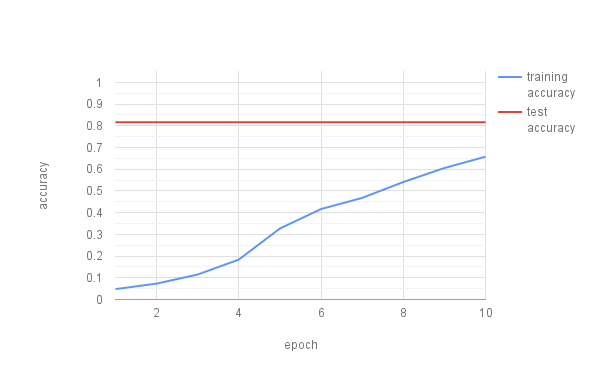
CNN with three conv. layers and two fully connected layers accuracy of CAPTCHAs with five digits or lowercase letters without rotation. Training in 199 batches, 49750 training samples, and testing with 500 CAPTCHAs.
Next, we added rotation to our CAPTCHAs and trained the CNN on 49782 samples. This resulted in almost random result with an accuracy around 10%. We thus increased the samples to 196926 and tested it on 500. Again, we kept the same hyperparameters as presented in the model section. This time we trained for 15 epochs, to prevent premature interruption of the training. Our results are presented in the figure below. With the increased training size we achieve a training accuracy of 97.1% and a test accuracy of 99.5%. However, this is again on a very small test set.
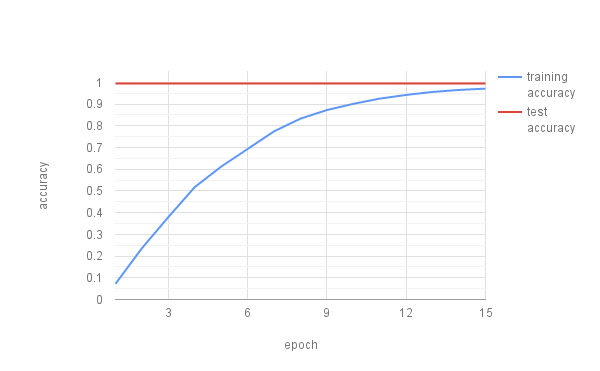
CNN with three conv. layers and two fully connected layers accuracy of CAPTCHAs with five digits or lowercase letters with rotation. Training in 787 batches, 196926 training samples, and testing with 500 CAPTCHAs.
From the tests conducted above, we have a few examples to show correct and false predictions.
| Correctly classified | Incorrectly classified |
|---|---|
| Prediction: 54563 Image: | Prediction: 82298 Image:  |
Prediction: grh56 Image:  | Prediction: k76ap Image:  |
Prediction: fb2x4 Image:  | Prediction: fffgr Image:  |
Conclusion
With this project we have shown that it is possible to create large enough datasets automatically to mimic certain CAPTCHAs (i.e. Microsoft). This provides large labeled datasets, which serve as a foundation to train neural networks. We have chosen to use two different CNNs with three and four convolutional layer and two fully connected layers. Our experiments show however, that adding more layers to the network did not increase the accuracy. We noticed that optimizing a CNN can be cumbersome. While running the CNN on a GTX 660M, we were not able to manage to get satisfying results. Most likely we would have needed more training time on the batches to receive better results. When we switched to a Tesla K80 we managed to train the network with larger amounts of data and a higher batch size. This resulted in higher accuracy on the simple and more complex datasets. We realized that memory poses a quite severe limitation towards applying large scale machine learning. Our approach based on a CNN is limited to CAPTCHAs with exactly the length defined in the network. Hence, classifying CAPTCHAs with any other length than five would fail. As an alternative a RNN could be used to resolve this issue. In [8] a use of RNN to break CAPTCHAs is discussed with fairly good results. However, also in this approach a powerful GPU is required. Moreover, using a CNN requires large datasets to be trained on. For a combination of digits, characters, and rotation we required a dataset of around 200000 CAPTCHAs (~780MB). On small sized GPU this datasets cause either out of memory errors or require a quite long training time. Even with the Tesla K80 the training time takes around 2 hours and 30 minutes.
References
- Goodfellow, Ian J., et al. "Multi-digit number recognition from street view imagery using deep convolutional neural networks." arXiv preprint arXiv:1312.6082 (2013).
- Hong, Colin et al. "Breaking Microsoft’s CAPTCHA." (2015).
- Using deep learning to break a CAPTCHA system in Deep Learning. 3 Jan. 2016, https://deepmlblog.wordpress.com/2016/01/03/how-to-break-a-CAPTCHA-system/. Accessed 6 Dec. 2016.
- Stark, Fabian, et al. "CAPTCHA Recognition with Active Deep Learning." Workshop New Challenges in Neural Computation 2015. 2015.
- Von Ahn, Luis, et al. "CAPTCHA: Using hard AI problems for security." International Conference on the Theory and Applications of Cryptographic Techniques. Springer Berlin Heidelberg, 2003.
- "CAPTCHA: Telling Humans and Computers Apart Automatically" 2010, http://www.CAPTCHA.net/. Accessed 7 Jan. 2017.
- Elie Bursztein et al., "The end is nigh: generic solving of text-based CAPTCHAs". Proceedings of the 8th USENIX conference on Offensive Technologies, p.3-3, August 19, 2014, San Diego, CA
- Recurrent neural networks for decoding CAPTCHAs in Deep Learning. 12 Jan. 2016, https://deepmlblog.wordpress.com/2016/01/12/recurrent-neural-networks-for-decoding-CAPTCHAs/. Accessed 9 Jan. 2017.
- CAPTCHA Alternatives and thoughts. 15 Dec. 2015, https://www.w3.org/WAI/GL/wiki/CAPTCHA_Alternatives_and_thoughts. Accessed 9 Jan. 2017.